고정 헤더 영역
상세 컨텐츠
본문
반응형
서브쿼리와 그룹함수
서브쿼리
- 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말한다.
- 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용한다.
서브쿼리 예시
|
select 칼럼1,칼럼2 FROM 테이블명 where 조건= (select.....from....where); |
조인과 서브쿼리의 분류
조인
- Join에 참여하는 모든 테이블이 대등한 관계에 있기 때문에 조인에 참여하는 모든 테이블의 칼럼을 어느 위치에서라도 자유롭게 사용할 수 있다.
서브쿼리
- 메인쿼리의 칼럼을 모두 사용할 수 있지만 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다.
- 질의 결과에 서브쿼리 칼럼을 표시해야 한다면 조인 방식으로 변환하거나 함수, 스칼라 서브쿼리 등을 사용해야 한다.
서브쿼리 사용시 주의점.
- 서브쿼리를 괄호"( )"로 감싸서 사용한다.
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능하다.
- 딘일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하이어야 하고 복수 행 비교 연산자는 서브쿼리의 결과 건수와 상관 없다.
- 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY절은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인쿼리의 마지막 문장에 위치해야 한다.
- 서브쿼리는 메인쿼리 안에 포함된 종속적인 관계이기 때문에 논리적인 실행순서는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족하는지를 확인하는 방식으로 수행되어야함.
서브쿼리 사용이 가능한 곳.
- SELECT 절(스칼라 서브쿼리)
- FROM 절
- WHERE 절
- HAVING 절
- ORDER BY 절
- INSERT문의 VALUES 절
- UPDATE문의 SET 절
동작하는 방식에 따른 서브쿼리 분류
|
서브쿼리 종류 |
설명 |
|
비 연관 서브쿼리 |
서브쿼리가 메인쿼리 칼럼을 가지고 있지 않는 형태의 서브쿼리 메인 쿼리에 값(서브쿼리가 실행된 결과)을 제공하기 위한 목적으로 주로 사용 |
|
연관 서브쿼리 |
서브쿼리가 메인쿼리 칼럼을 가지고 있는 형태의 서브쿼리 메인쿼리가 먼저 수행되어 읽혀진 데이터를 서브쿼리에서 조건이 맞는지 확인하고 할 때 주로 사용한다. |
반환되는 데이터 형태에 따른 서브쿼리 분류
|
서브쿼리 종류 |
설명 |
|
단일행 서브쿼리 |
서브쿼리의 실행 결과가 항상 1건 이하인 서브쿼리를 의미한다. 단일행 서브쿼리는 단일행 비교 연산자와 함께 사용된다. 단일행 비교 연산자에는 =, <, <=, >, >=, <>이 있다. |
|
다중행 서브쿼리 |
서브쿼리의 실행 결과가 여러개인 서브쿼리를 의미한다. 다중행 서브쿼리는 다중행 비교 연산자와 함께 사용된다. 다중행 비교 연산자에는 IN, ALL, ANY, SOME, EXISTS가 있다. |
|
다중 칼럼 서브쿼리 |
서브쿼리의 실행 결과로 여러 칼럼을 반환한다. 메인쿼리의 조건절에 여러 칼럼을 동시에 비교할 수 있다. 서브쿼리와 메인 쿼리에서 비교하고자 하는 칼럼 개수와 칼럼의 위치가 동일해야한다. |
단일 행 서브쿼리
- 서브쿼리가 단일 행 비교 연산자(=,<=,<,>=,>,<>)와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 이하이어야 한다.
- 그렇지 않으면, SQL문은 RunTime 오류가 발생한다.
단일 행 서브쿼리 예시1.
|
정남일 선수가 소속된 팀의 선수들에 대한 정보를 표시하는 서브쿼리 SQL문을 보여라 |
|
select player_name 선수명, position 포지션, back_no 등번호 (select team_id from player where player_name='정남일') |
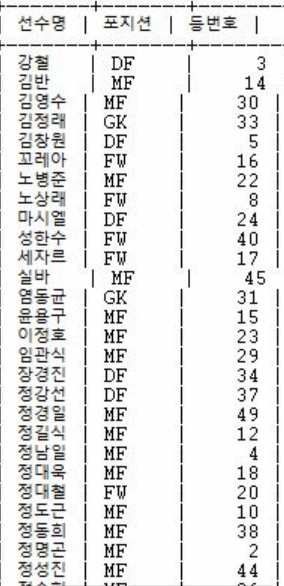
|
단일 행 서브쿼리 예시2.
|
선수들의 평균키를 알아내는 SQL문(서브쿼리 부분)과 이 결과를 이용해서 키가 평균 이하의 선수들의 정보를 출력하는 SQL문을 알려주세요 |
|
select player_name 선수명, position 포지션, back_no 등번호 |
 |
다중 행 서브쿼리
- 서브쿼리의 결과가 2건 이상 반환될 수 있다면 반드시 다중 행 비교 연산자(IN,ALL,ANY,SOME)와 함께 사용해야 한다.
다중 행 비교 연산자
|
다중행 연산자 |
설명 |
|
IN(서브쿼리) |
서브쿼리의 결과에 존재하는 임의의 값과 동일한 조건을 의미한다. |
|
ALL(서브쿼리) |
서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건을 의미한다. 비교 연산자로 ">"를 사용했다면 메인 쿼리는 서브쿼리의 모든 결과 값을 만족해야 하므로, 서브쿼리 결과의 최대값보다 큰 모든 건이 조건을 만족한다. |
|
ANY(서브쿼리) |
서브쿼리의 결과에 존재하는 어느 하나의 값이라도 만족하는 조건을 의미한다. 비교 연산자로">"를 사용했다면 메인쿼리는 서브쿼리의 값들 중 어떤 값이라도 만족하면 되므로, 서브쿼리의 결과의 최소 값보다 큰 모든 건이 조건을 만족한다. |
|
EXISTS(서브쿼리) |
서브쿼리의 결과를 만족하는 값이 존재하는지 여부를 확인하는 조건을 의미한다. 조건을 만족하는 건이 여러 건이더라도 1건만 찾으면 더 이상 검색하지 않는다. |
다중 행 서브쿼리 예제1.
|
선수들 중에 '정현수'라는 선수가 소속되어 있는 팀 정보를 출력하는 서브쿼리 작성 |
|
select region_name 연고지, team_name 팀명, e_team_name 영문팀명
1242 - Subquery returns more than 1 row
단일행 서브쿼리를 사용할 경우 서브쿼리가 1개 이상 나온다는 에러가 나오므로 다중 행 서브쿼리를 사용한다. |
|
select region_name 연고지, team_name 팀명, e_team_name 영문팀명 |
 |
다중 칼럼 서브쿼리
- 서브쿼리의 결과로 여러 개의 칼럼이 반한되어 메인쿼리의 조건과 동시에 비교되는 것을 의미한다.
예제.
|
소속팀별 키가 가장 작은 사람들의 정보를 출력하세요. |
|
select team_id 팀코드, player_name 선수명, position 포지션, (소속팀별 최소 키 이므로 소속팀을 Group by 해준다.) |

|
연관 서브쿼리
- 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리이다.
예제.
|
선수 자신이 속한 팀의 평균 키보다 작은 선수들의 정보를 출력하시오. |
|
select t.team_name 팀명, p.player_name 선수명, p.position 포지션, |
 |
뷰
- 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블이라고 함.
뷰 사용 장점
|
뷰의 장점 |
설명 |
|
독립성 |
테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다. |
|
편리성 |
복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다. 해당 형태의 SQL문을 자주 사용할 때 뷰를 이용하면 편리하게 사용할 수 있다. |
|
보안성 |
직원의 급여정보와 같이 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 때 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있다. |
뷰 테이블 생성 방법.
|
CREATE VIEW 뷰 테이블명 AS SELECT ..... FROM ..... WHERE ..... |
데이터 분석 개요
* Aggregate Function
- Group Function의 한 부분으로 Count, Sum, Avg, Max, Min외 각종 집계함수들이 포함.
* Group Function
- 결산 개념의 업무를 가지는 원가나 판매 시스템의 경우는 소계, 중계, 합계, 총 합계 등 여러 레벨의 결산 보고서를 만드는 것이 중요 업무중 하나이다.
- 그룹합수로는 집계 함수를 제외하고, 소그룹 간의 소계를 계산하는 Rollup Function.
- Group By 항목들간 다차원적인 소계를 계산 할 수 있는 Cube Function.
- 특정 항목에 대한 소계를 계산하는 Grouping Sets.
* Window Function
- 분석함수나 순위함수로도 알려져 잇으며 데이터웨어하우스에서 발전한 기능이다.
Roll up Function
- Group By의 확장된 형태로 사용하기가 쉬우며 병렬로 수행이 가능하기 때문에 매우 효과적일 뿐 아니라 시간 및 지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합하도록 되어 있다.
- Roll up에 지정된 Grouping Columns의 List는 Subtotal을 생성하기 위해 사용되어 진다.
- Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성된다.
- Roll up의 인수는 계층구조이므로 인수 순서가 바뀌면 수행 결과도 바뀌게 되므로 인수의 순서에도 주의해야 한다.
Cube Function
- Roll up에서는 단지 가능한 Subtotal만을 생성하였지만, Cube는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
- Cube를 사용할 경우에는 내부적으로는 Grouping Column의 순서를 바꾸어서 또 한 번의 Query를 추가 수행해야 한다. 뿐만 아니라 Grand Total은 양쪽의 Query에서 모두 생성이 되므로 한 번의 Query에서는 제거되어야만 하므로 Roll up에 비해 시스템의 연산 대상이 많다.
- 표시된 인수들에 대한 계층별 집계를 수할 수 있으며, 이때 표시된 인수들 간에는 계층구조인 Rollup과는 달리 평등한 관계이므로 인수의 순서가 바뀌는 경우 행간에 정렬 순서는 바뀔수 있어도 데이터 결과는 같다.
반응형
'IT > SQLD(SQL개발자)' 카테고리의 다른 글
| [SQLD] 조인 종류와 수행 원리 (0) | 2019.07.05 |
|---|---|
| [SQLD] 옵티마이저와 테이블 스캔 (0) | 2019.07.04 |
| [SQLD] 집합연산자와 계층형 질의 (0) | 2019.07.02 |
| [SQLD] SQL 기본 및 활용(SQL 기본) 정리 및 표준조인(Standard Join) (0) | 2019.07.01 |
| [SQLD] ORDER BY 와 JOIN (0) | 2019.06.30 |






댓글 영역